2026 AI 에이전트 메모리 운영법: 장기기억·세션기억 분리로 품질 높이는 실전 체크리스트 7가지
AI 자동화를 오래 운영하면 가장 먼저 부딪히는 문제는 모델 성능 자체보다 기억 관리입니다. 같은 요청인데 세션마다 답이 달라지거나, 과거 결정사항을 놓쳐 재작업이 반복되면 운영 비용이 급격히 올라갑니다. 2026년 실무에서는 이 문제를 해결하기 위해 단기 대화 컨텍스트와 장기 지식 저장소를 분리하는 메모리 아키텍처를 표준으로 도입하고 있습니다. 이 글은 장기기억·세션기억 분리 전략을 현업에서 바로 적용할 수 있도록 체크리스트 중심으로 설명합니다.
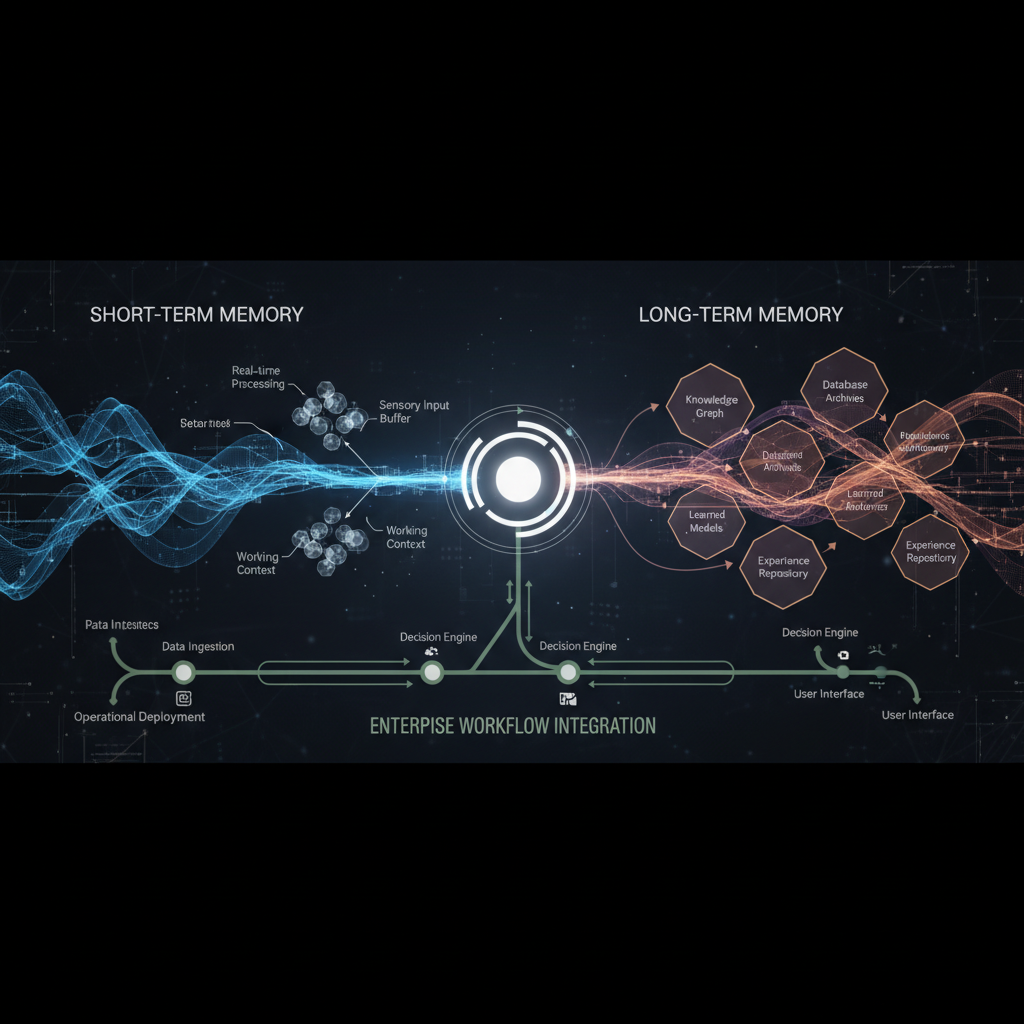
1) 단기기억과 장기기억을 분리해야 하는 이유
원리 설명
세션기억은 현재 작업 맥락을 빠르게 처리하는 데 유리하지만, 시간 경과에 따른 품질 저하가 큽니다. 반면 장기기억은 정책, 선호, 과거 의사결정을 축적해 일관성을 높입니다. 두 영역을 분리하면 응답 속도와 정확도를 동시에 관리할 수 있습니다. 이 구조는 운영 안정성의 기본 토대가 됩니다.
실수 사례
모든 정보를 프롬프트에 누적해 토큰 비용이 폭증하는 경우가 많습니다. 장기 정책을 세션 문맥에만 의존해 재시작 시 누락되는 문제도 반복됩니다. 반대로 장기 저장소를 과신해 최신 문맥 반영이 늦어지는 오류도 생깁니다. 분리 없는 구조는 품질 편차를 키웁니다.
실행 방법
정책·선호·결정사항은 장기 메모리 문서로 저장하고, 작업 지시와 임시 상태는 세션기억에서만 다룹니다. 장기 메모리 조회는 질문 유형에 맞춰 선별적으로 수행해 과도한 주입을 피하세요. 세션 종료 시 핵심 변경사항만 큐레이션해 장기 저장소로 승격합니다. 이 흐름을 루틴으로 고정하면 일관성이 높아집니다.
주의점
저장 기준이 없으면 장기기억이 잡음으로 오염될 수 있습니다. 민감 정보는 접근 통제를 선행해야 합니다. 세션기억과 장기기억의 우선순위 충돌 규칙도 미리 정해야 합니다. 기준 없는 자동 저장은 장기적으로 품질을 떨어뜨립니다.
2) 메모리 검색 품질: 정확도와 비용의 균형
원리 설명
메모리 검색은 많이 불러오는 것보다 필요한 정보만 정확히 가져오는 것이 중요합니다. 과다 검색은 토큰 비용과 응답 지연을 키우고, 과소 검색은 맥락 누락을 만듭니다. 따라서 질의 유형별 검색 폭과 점수 임계치를 조정해야 합니다. 검색 정책은 모델 성능만큼 중요한 품질 변수입니다.
실수 사례
모든 질문에 동일한 검색 범위를 적용해 불필요한 문맥을 주입하는 경우가 많습니다. 검색 점수 임계치 없이 상위 결과를 그대로 주입해 노이즈가 늘어나기도 합니다. 메모리 파일을 갱신하지 않아 오래된 정책이 계속 참조되는 문제도 흔합니다. 이 조합은 답변 신뢰도를 낮춥니다.
실행 방법
업무 유형별로 검색 템플릿을 분리해 조회 범위를 제한하세요. 정책성 질문은 장기기억 우선, 실행성 질문은 최근 로그 우선으로 라우팅하면 효과적입니다. 검색 결과는 스니펫 단위로 확인 후 필요한 줄만 주입해 비용을 줄입니다. 주간 점검으로 오탐/누락 사례를 수집해 임계치를 보정하세요.
주의점
검색 성능 개선을 모델 교체로만 해결하려 하면 비용이 급증할 수 있습니다. 먼저 쿼리 설계와 저장 구조를 점검해야 합니다. 임계치 변경은 A/B 비교 없이 적용하면 품질 변동이 큽니다. 데이터 기반 튜닝이 필수입니다.
3) 운영 거버넌스: 메모리 업데이트 승인 루프
원리 설명
메모리는 시스템의 장기 행동을 바꾸는 설정이므로 업데이트 통제가 필요합니다. 누구나 임의로 장기기억을 수정하면 정책 일관성이 무너질 수 있습니다. 승인 루프를 두면 잘못된 정보 주입과 정책 충돌을 줄일 수 있습니다. 거버넌스는 속도를 늦추는 장치가 아니라 품질을 지키는 장치입니다.
실수 사례
작업 중 발견한 임시 정보를 즉시 장기기억에 반영해 오류가 고착되는 경우가 있습니다. 승인 이력 없이 수정해 원인 추적이 어려워지는 사례도 많습니다. 삭제 기준이 없어 오래된 규칙이 누적되는 문제도 반복됩니다. 결과적으로 메모리 신뢰도가 하락합니다.
실행 방법
장기기억 수정은 제안-검토-반영 3단계로 운영하세요. 수정 항목마다 근거, 유효기간, 적용 범위를 명시하면 유지보수가 쉬워집니다. 정기 정리 작업에서 오래된 항목을 아카이브해 검색 효율을 높입니다. 변경 로그를 남겨 회고 시 재발 방지에 활용하세요.
주의점
승인 절차가 과도하면 현장 활용성이 떨어질 수 있습니다. 핵심 정책과 일반 메모를 구분해 절차를 차등 적용하는 것이 좋습니다. 긴급 수정 경로도 사전에 정의해야 혼선을 줄일 수 있습니다. 문서화와 실행을 함께 관리해야 실효성이 생깁니다.
4) 실전 체크리스트 7가지
핵심 항목
첫째, 단기/장기 메모리 저장 기준을 문서화합니다. 둘째, 질문 유형별 검색 템플릿을 분리합니다. 셋째, 검색 점수 임계치와 주입 길이를 설정합니다. 넷째, 장기기억 수정 승인 루프를 고정합니다.
운영 항목
다섯째, 주간 오탐/누락 리포트를 작성합니다. 여섯째, 월간 아카이브로 오래된 규칙을 정리합니다. 일곱째, 비용·정확도 지표를 함께 추적해 튜닝합니다. 이 7가지는 소규모 팀에서도 즉시 적용 가능합니다.
주의점
체크리스트는 작성보다 실행률이 중요합니다. 담당자와 주기를 명확히 해야 유지됩니다. 자동화 가능한 부분은 스크립트로 고정해 누락을 줄이세요. 작은 루틴이 장기 품질을 만듭니다.
FAQ
Q1. 메모리를 많이 쌓을수록 좋은가요?
아닙니다. 필요한 정보만 정확히 유지하는 것이 중요합니다. 과도한 저장은 검색 노이즈를 늘립니다. 큐레이션이 품질의 핵심입니다.
Q2. 장기기억 업데이트는 얼마나 자주 해야 하나요?
중요 결정이 있을 때 즉시 반영하되, 정기 점검은 주간/월간으로 나누는 것이 좋습니다. 실시간 반영과 주기 정리를 함께 운영해야 안정적입니다. 변경 로그를 반드시 남기세요. 추적성이 재발 방지에 도움이 됩니다.
Q3. 비용이 늘면 무엇부터 점검해야 하나요?
모델 교체 전에 검색 폭, 주입 길이, 캐시 정책을 먼저 점검하세요. 많은 경우 구조 조정만으로도 비용을 줄일 수 있습니다. 단계별 KPI가 있으면 원인 파악이 빠릅니다. 데이터 기반 개선이 가장 안전합니다.
마무리
AI 메모리 운영의 핵심은 더 많이 기억하는 것이 아니라 더 정확히 기억하는 것입니다. 단기와 장기를 분리하고, 검색 정책과 승인 루프를 고정하면 비용과 품질을 동시에 관리할 수 있습니다. 오늘은 저장 기준 문서화부터 시작해 보세요. 작은 표준화가 장기 운영 신뢰도를 높입니다.
댓글
댓글 쓰기